Action Recognition
Dr.Sure最近看了一些视频中动作识别的文章,10天左右的时间,一共撸了14篇相关的论文。这里就做一下总结。
首先动作识别属于分类任务的一种,而更确切的说是属于视频分类的一种。
因为一般情况下,虽然我们可以通过单帧判断里面人物的动作,但是难免会不准确。例如一个人站在镜头前,可能在摆拍也可能在对着镜头跳舞,这时候单独靠静态图像就很难解决这个问题。所以这个时候对视频的理解就显得尤为重要。
一、Outline
首先来介绍一下处理这类问题的大致方向。下面这个图给出了比较好的理解。
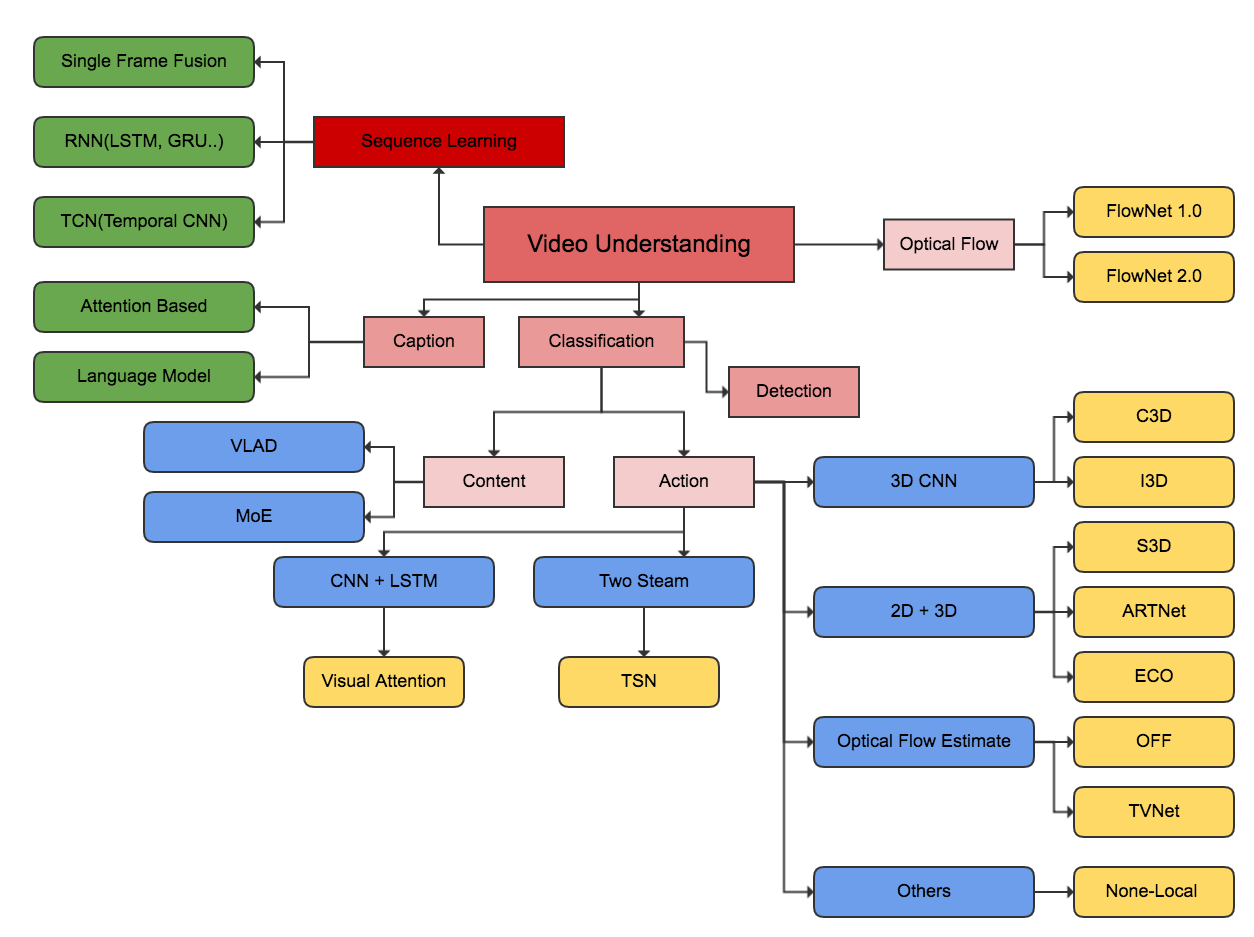
向上,视频理解属于序列化学习一部分;向下视频理解分成视频转文字(Caption)、视频分类(Classification)以及视频事件(动作)检测(Action Recognition)。
视频动作识别属于视频分类的一部分,视频分类又可以分成基于内容的和基于运动信息两种。这两者唯一的不同就是标签体系。运动数据集,里面全是一些运动相关的标签,单一帧信息无法区别这些标签,所以这类任务天然就需要从视频维度求解。而基于内容的可以理解为涵盖面更加广,例如Youtube-8M数据集,这里面大部分的标签可能通过单张图像就能分类,但是也有需要视频求解的标签。
基于内容的视频理解后面Dr.Sure会专门抽出一篇文章进行讲解,下面就动作识别做一个系统的总结。
1. CNN + RNN
这个是最经典的搭配模式,包括现在大多数的Caption依然采用这种网络结构,CNN作为特征提取器(Encoder),RNN作为特征的解码器(Decoder)。
作为视频理解,目前大家都会引入一些Attention的机制在这个里面,让Encoder和Decoder更加精细。
但是无论使用何种Attention的技术,使用2dCNN一个永远无法跨越的鸿沟就是时序信息的问题,虽然RNN可以对这个信息进行一定的编码,但是CNN提取出来的特征,由于帧与帧之间相差太小,让RNN去捕捉这个微小的变化简直太困难,加上RNN本身不好训练的问题,所以这个模型逐渐被后面的方法代替。
2. Two Steam
双流法,顾名思义就是两种信息流被用来对动作进行预测。
Optical Flow
光流,这个是用来计算帧与帧之间像素点的变化信息,这个信息对于动作识别来说简直不要太有用,因为动作说白了就是像素点之间的变化信息。
但是光流信息计算的时间复杂度太高了,计算光流的时间消耗基本上占到处理视频的90%以上的时间,所以后面就有人提出来了用CNN去提取光流图的方法,比较有代表性的就是FlowNet1.0和FlowNet2.0。
RGB
光流只能表现视频中像素的变化信息,换句话说就是它能够对视频的时序(Temporal)信息进行很好的建模,但是对于物体(Appearance)信息就显得捉襟见肘,另外一个信息源,RGB就是为了解决这个Appearance的问题。
Combine
最后这双流的模型Combine比较简单,就是将两种信息提取的特征进行Concat或者在用个DNN网络融合一下,最后到了Softmax的分类损失。
3. 3D CNN
3D CNN是2D卷积在时序维度上的一个扩展,2D CNN一般用于提取的是图像的特征,而3D多的这个维度提取的是时间信息。3D的卷积目前被广泛用在了视频维度的内容理解领域。
3D卷积的使用非常简单,跟2D的卷积是相类似的。但是有一个细节与2D的卷积不同。
在2D卷积中,前一层网络的输出的通道个数在下一层中是可以发生改变的即前一层特征图的大小·[batch_size, height, width, shap1],下一层可以使用一个[shape1, kernel_height, kernel_width, shape2]这样的卷积核使通道数从shape1→shape2。
在3D卷积中,最后一个时间通道数并不会发生变化,这个3D卷积的最后一维的时间stride是固定死的,这一点与2D卷积有所不同(但是空间通道数依然可变)。
4. End2End
除了上面说的三种主流方法,目前还有一类的方法就是端到端地训练一个动作识别的模型(不像C3D需要提取时间信息、也不像TwoSteam引入光流特征)。
这类方法的基本思路就是使用卷积去提取那些像素中的变化,换句话说就是不再单独计算光流,而是通过一种算子,直接去模拟光流图的计算方式,并将提取出来的特征融入到网络中。
如果您感觉这篇文章对您有用,就打赏一下作者以资鼓励 :)
